



Since 2019, our IT services company has been developing an innovative solution for furniture stores – 3D visualization platform Zolak. With its help, users can try on different types of furniture in their interiors.
Everything looks quite simple: old furniture disappears, and new furniture appears in its place. However, as is usually the case, there is more behind the apparent simplicity. In our case, these are neural networks. They do all the rough work: they define objects and restore the interior after their removal.
In two years of working with neural networks, we have learned how to train them faster and better – all at a lower cost. And now, we want to share this experience with you.
How neural networks create competitive advantage for companies and why data is the “new gold”
First, we need to understand – why is it worth paying attention to the neural networks.
Computer vision technology, and neural networks in general, are becoming more and more popular. Its usage can be found in many applications, from masks in MSQRD, to trying on sneakers. Even Tesla uses the technology, detecting and tracking objects from its onboard cameras for autopilot. In each case, such functionality distinguishes applications from their competitors.

Tesla’s autopilot detects objects
Examples of companies using artificial intelligence as a competitive advantage do not end there.
The success of apps like Netflix, Uber, and Instagram is not in their idea. Even before them, there were video-streaming apps, taxis, and social networks. Their success is in the technology they use, particularly, in the data they collect and use.
Every click, every scroll, and every other “user event” gets into their database to be analyzed later. All their activities are focused on ensuring your user experience is close to perfect. No person can analyze such a volume of data, and here again, neural networks come to the rescue.
Considering all these examples, we can draw a logical conclusion: today, access to a large amount of user data and neural networks is a key competitive advantage in the market.
What is a neural network, and how it works
What is a neural network
A neural network (or artificial neural network) is a mathematical model and its software and hardware implementation. The network is modeled based on a biological neural network, in which neurons are connected through synapses. This is exactly how it got its name.
Usually, a neural network consists of 3 layers of neurons:
- An input layer, by which the input signals are distributed to the rest of the neurons;
- Hidden layer (or layers) that convert input signals into intermediate results ;
- And the output layer that outputs the response.
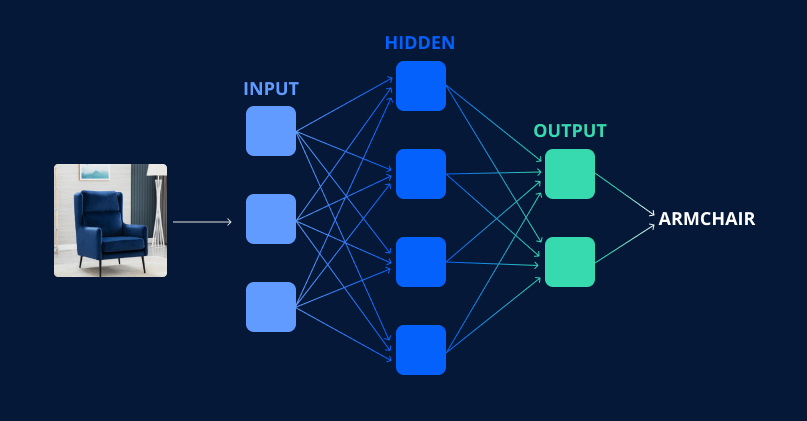
Simple neural network diagram
Neural networks are used to solve various problems. They are used to make forecasts, recognize objects, solve management tasks, and much more. Each has its own specifics.
In this article, we will look closer at the work of a neural network in object recognition.
What is a dataset
Just like a biological network, an artificial neural network gains knowledge through training over time. For this training, we need to prepare special datasets.
A dataset is a set of data collected for a specific purpose. The data can be in various formats. In our case, this is a processed set of photos suitable for processing by machine learning algorithms.

Example of a dataset
Such a sample is needed to train a neural network to use it later for solving real problems.
How neural networks are trained
A neural network can be compared to a child learning something new. At first, it is difficult to solve problems well, but the more experience a network has, the better it does it.
The network must understand what is “good” for solving a problem, and what is “bad” to learn. To do this, we need to determine characteristics, based on which the neural network makes a decision.

The neural network learns like a child
For example, to correctly identify an object, the network must understand what shape this object is, what material it consists of, how it interacts with the space around it, etc.
At the initial stages of training a neural network, these signs are simple, for example, we define a table by four legs and a tabletop. However, the longer we train the network, the more characteristics it operates on. At some stage, we can no longer say exactly how the neural network identified the same table in the photo.
Considering there can be thousands, or even millions, of options of the searched object, a clear definition of objects and their replacement are complex tasks. You want your app to detect them all. The cornerstone of success is the accuracy of object detection by the neural network.
Often, such tasks are solved simply by scaling up the dataset. The neural network receives more input data, gains more ” experience”, and accordingly defines objects with greater accuracy.
To some extent, this works, but the further the project develops, the larger the dataset is needed. And, the larger the dataset, the more investment and control over the infrastructure are needed.
At such moments, you wonder how effective the current training process is and whether it can be improved.
How to improve the efficiency of a neural network
Efficiency is a relative value that shows the ratio between the achieved result and the used resources.
Where to start
To start, we need to understand whether we need it at all. Yes, the resources invested in improvements do not always lead to positive results.
So, developers often sin by spending too much time on improving technical characteristics that do not affect the development of the business. The requirements of business representatives may be unrealistic due to a lack of understanding of the complexity of the technical task. That is why decisions to improve the product are always made because of a dialogue between the technical and business sides of the company.

Dialogue between the technical and business sides of the company
In our case, we set a goal: to increase the percentage of object recognition accuracy by the neural network with the minimum amount of dataset.
Since the basis of our dataset is images, we had to dive into the very basics of the image – what it consists of. We have developed an approach that can be used in various tasks related to computer vision and object recognition in images.
Structure and texture
All the objects that we see around us comprise of structure and texture.
The structural layer is a smoothed version of the image, free of “minor” details called texture.
Textures are repeated patterns that are regularly or irregularly distributed in the structure of an object. Examples of texture: different roughness on the surface of the table, reflections of light, shadows, etc.

Images with and without texture
Over the years of evolution, the human visual system has learned to filter the texture layer skillfully. Thus, psychological studies show that general structural features are the primary data of human perception. We simply don’t pay enough attention to the texture.
The same can’t be said for a computer, however.
Both structure and texture play an important role in object recognition. Ten years ago, computer vision researchers manually developed many structure-and texture-based functions for recognizing objects. They found that the right combination of them can improve recognition, demonstrating superiority over both characteristics separately.
Currently, thanks to the popularization of convolutional neural networks(CNN), the characteristics used for object recognition are determined automatically, rather than being developed manually.
Convolutional neural network – a unique architecture of neural networks aimed at efficient image recognition.
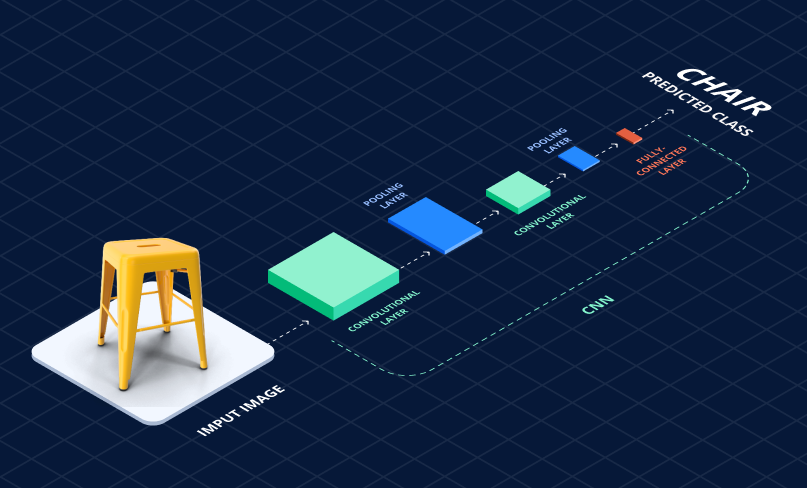
How a convolutional neural network works
This change facilitated human efforts to design recognition algorithms and significantly improved the performance of neural networks. There is no need for a person to consider each particular case; the neural network now recognizes the characteristics.
However, automation has also negatively adjusted object recognition. It was proved that functions studied by CNN bias towards the structure or texture, depending on the content of the dataset.
It has become more difficult for the neural network to strike a balance between the characteristics associated with structure and texture. As a result, it cannot achieve its maximum performance.
The above prompted us to look closely at the interaction of texture and structure when defining objects.
How structure and texture interact with each other when defining objects
To understand how texture and structure interact, we have prepared models biased in both directions, respectively.
To do this, using a special algorithm, we separated the texture from the structure in the images, then prepared the corresponding datasets and trained the models on them.
As expected, models biased to texture and structure have worse recognition accuracy than their conventional, less biased counterparts. The model focused on the structure-determined objects with an accuracy of 91.7%, and the model trained on the texture – with an accuracy of 91.5%. While the original model had an accuracy of 92%.
Despite this, we found that they are highly complementary to each other. As we can see in the figure, models biased to structures and textures use different signals for their predictions.

The attention of biased models is focused on different features
For example, in the middle photo, the model biased to structure mainly focuses on the outer edges of the armchair, and the model with an emphasis on texture on armchair material, using the shape and the texture of the armchair, respectively.
This allowed us to assume the current model, which is automatically biased towards the structure or the texture, can be improved. To do this, we need to teach the model to find a balance between texture and structure.
How we improved the efficiency of neural network training
To teach the model to find a balance between texture and structure, we have prepared a new framework based on assigning labels to images.
To do this, we prepare a dataset in advance in which we assign special labels: s – for images with a structure and t – for images with a texture. Next, while training the neural network, we try to determine the third “ideal” label “y” using the following formula:
y=k*s+(1-k)*t
where k is a manually selected coefficient from 0 to 1, which allows you to control the relative importance of texture and structure when defining an object.
By changing the coefficient k from 0 to 1, we can evolve the model from being focused on texture(where k=0), to a model focused on structure(where k=1). Although both of these extremes lead to poor model performance, we have determined that there is an “ideal” point on this segment that allows us to find a balance between structure and texture when defining objects.
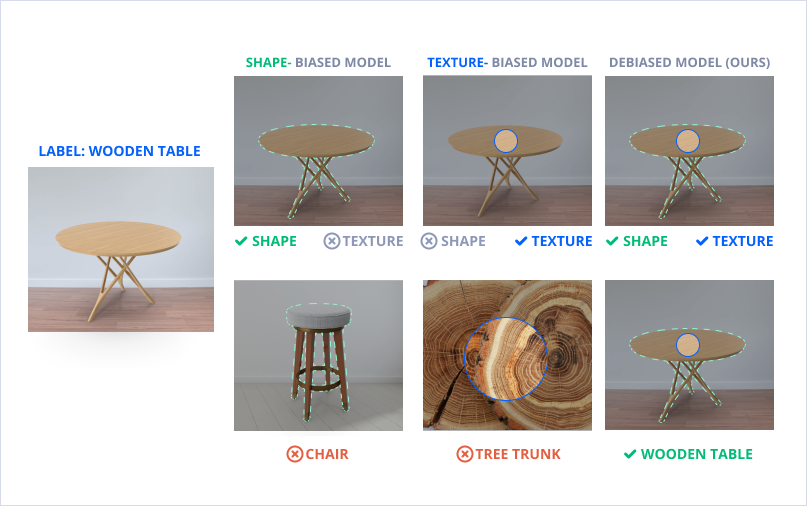
How our model defines objects
This approach allowed us to increase the percentage of recognition of furniture items from 92% to 93.2%, while the amount of dataset required for training was significantly reduced from 97500 samples to 39000 samples. This allowed us to reduce the costs of dataset management and training time by 40-50%.
Conclusion
The success of a company in our time is closely related to how technologically advanced it is. The better its products, the more effectively they perform their task, the more likely the company is to win the competition in the market.
That is why such giants as Google and Microsoft hire people who understand how the product works superficially and from the inside. Only by understanding how the basis works you can make a qualitative leap and create a truly innovative product.
Our example shows how even such a small improvement in efficiency can bring significant results. This approach can solve various problems related to the definition of objects in images and subsequent work with them.
Scale your team with premium-class remote developers with 5+ years of experience and the expertise you require.
Let's Talk



